1 INTRODUCTION
VGGNet是由牛津大学和Google DeepMind团队提出的,他们在ILSVRC-2014定位任务夺得第一名,分类任务获得第二名(GoogleNet是分类任务的第一名)。VGGNet具有很好的泛化能力,在其他数据集上也有较好的表现。
卷积网络现在在大规模图像和视频识别中取得了巨大的成功,成为了计算机视觉领域的常用工具。AlexNet是具有重要意义的网络结构,有很多人企图改进ALexNet,比如:ZFNet。ZFNet在第一卷积层使用更小的卷积(receptive window size)和更小的步长(stride),而VGGNet强调了卷积神经网络设计中另一个重要方面—深度。并且VGGNet在所有层使用3*3的卷积核。
2 CONVNET CONFIGURATIONS
为了公平测试深度带来的性能提升,VGGNet所有层的配置都遵循了同样的原则。
2.1 ARCHITECHTURE
- 唯一的预处理 :训练集中的每个像素上减去RGB的均值 ;
- 训练时,输入是固定大小的224 * 224 RGB图像;
- 使用了非常小的感受野(receptive field):3 * 3,甚至有的地方使用1 * 1的卷积,这种1 * 1的卷积可以被看做是对输入通道(input channel)的线性变换,卷积步长是1个像素;
- 池化层 采用max-pooling,共有5层,max-pooling的窗口是2 * 2,步长是2;
- 一系列卷积层之后跟着全连接层(fully-connected layers)。前两个全连接层均有4096个通道。第三个全连接层有1000个通道,用来分类。所有网络的全连接层配置相同。
- 最后一层是soft-max层
注: 所有隐层使用激活函数是ReLu .VGGNet不使用局部响应标准化(LRN),这种标准化并不能在ILSVRC数据集上提升性能,却导致更多的内存消耗和计算时间。
2.2 CONFIGURATIONS
Table1给出了所有的网络配置
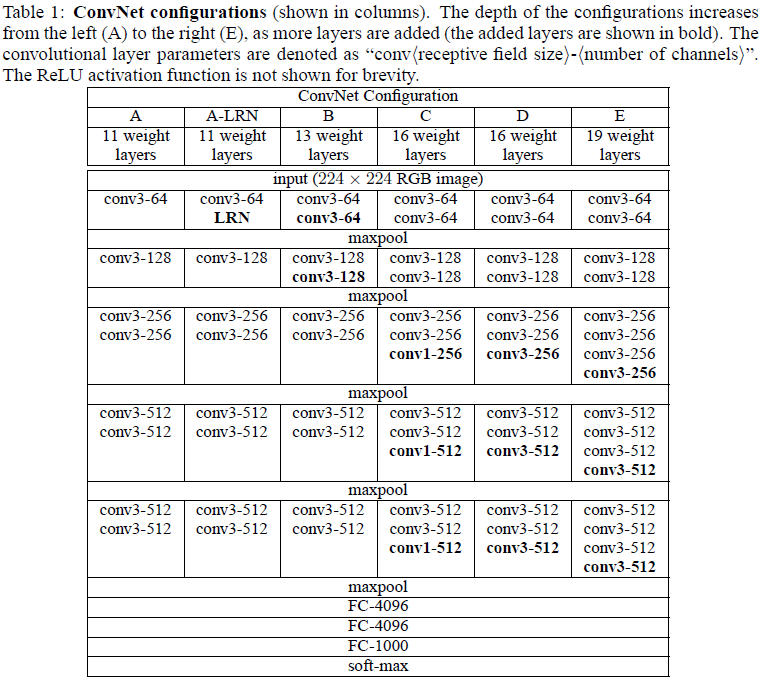
2.3 DISCUSSION
相比于AlexNet和ZFNet,VGGNet在网络中使用很小的卷积。AlexNet和ZFNet在第一个卷积层的卷积分别是11 * 11 with stride 4和7 * 7 with stride 2。
VGGNet使用三个3 * 3卷积而不是一个7 * 7的卷积的优势有两点:一,包含三个ReLu层而不是一个,使决策函数更有判别性;二,减少了参数。比如输入输出都是C个通道,使用3 * 3的3个卷积层需要3(3 * 3 * C * C)=27 * C * C,使用7 * 7的1个卷积层需要7 * 7 * C * C=49C * C。这可看为是对7 * 7卷积施加一种正则化,使它分解为3个3 * 3的卷积。
1*1卷积层主要是为了增加决策函数的非线性,而不影响卷积层的感受野。虽然1 * 1的卷积操作是线性的,但是ReLu增加了非线性。
GoogleNet采用了更深更复杂的网络结构(22层),多种卷积核(1 * 1,3 * 3, 5 * 5),并且在第一层中特征比VGGNet更少。
3 CLASSIFICATION FRAMEWORK
3.1 TRAINING
- 优化函数:SGD+momentum(0.9)
- batch size:256
- 正则:采用L2正则化,weight decay是5e-4;dropout在前两个全连接层后,p=0.5。
- 参数初始化:随机初始化,权重w从N(0,0.01)中采样,偏差bias初始化为0。
- 为了获得224*224的输入图像,要在每个sgd迭代中对每张重新缩放(rescale)的图像随机裁剪。为了增强数据集,裁剪的图像还要随机水平翻转和RGB色彩偏移。
尽管相比于AlexNet网络更深,参数更多,但是我们推测VGGNet在更少的周期内就能收敛,原因有二:一,更大的深度和更小的卷积带来隐式的正则化;二,一些层的预训练。
3.2 TESTING
测试阶段步骤:
- 对输入图像各向同性地重缩放到一个预定义的最小图像边的尺寸Q;
- 网络密集地应用在重缩放后的测试图像上。也就是说全连接层转化为卷积层(第一个全连接层转化为7 * 7的卷积层,后两个全连接层转化为1 * 1的卷积层) ,然后将转化后的全连接层应用在整张图像上。结果就是一个类别分数图(class score map),其通道数等于类别数量,依赖于图像尺寸,具有不同的空间分辨率;
- 为了获得固定尺寸的类别分数向量(class score vector),对class score map进行空间平均化处理(sum-pooled)。
3.3 IMPLEMENTATION DETAILS
基于C++ Caffe, 在4个Titan GPU上训练了2-3周。
4 CLASSIFICATION EXPERIMENTS
4.1 SINGLE SCALE EVALUATION
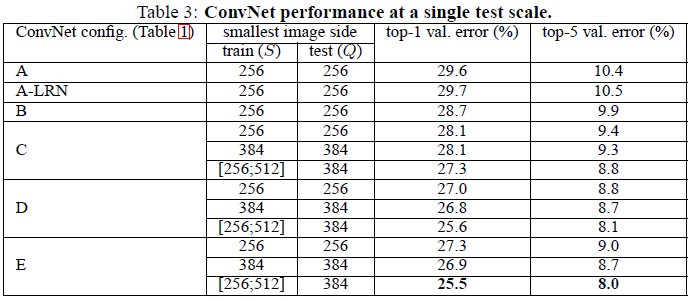
通过分析Table3结果,得出如下结论:
- 我们发现使用local response normalization(A-LRN)并不能改善A网络性能。
- 分类误差随着深度增加而降低。
- 在训练时采用图像尺度抖动(scale jittering)可以改善图像分类效果。
4.2 MULTI-SCALE EVALUATION
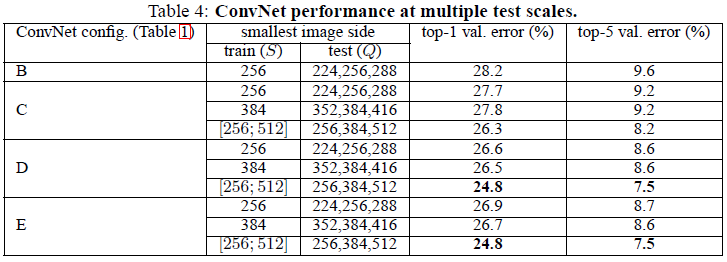
通过分析Table4结果,得出如下结论:
- 相对于单一尺度评估,多尺度评估提高了分类精度。
- 在训练时采用图像尺度抖动(scale jittering)可以改善图像分类效果。
4.3 MULTI-CROP EVALUATION
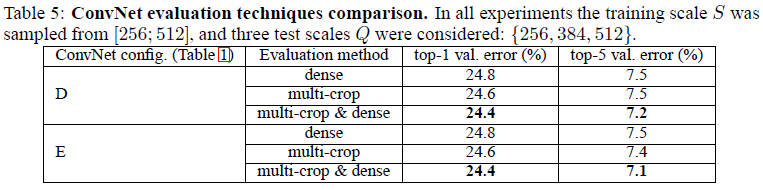
多裁剪(multi-crop)评估比起密集(dense)评估,效果更好。而且两者具有互补作用,结合两种方式,效果更好。
4.4 CONVNET FUSION

通过分析Table6结果,得出如下结论:
- 如果结合多个卷积网络的sofamax输出,分类效果会更好。
- 在ILSVRC-2014中,我们结合7个网络,实现测试误差7.3%。之后,结合最好的两个模型(D&E)并使用密集评估(dense evaluation),测试误差降低到7.0%,而使用密集评估和多裁剪评估相结合,测试误差为6.8%。最好的单一模型验证误差为7.1%。
4.5 COMPARISON WITH THE STATE OF THE ART
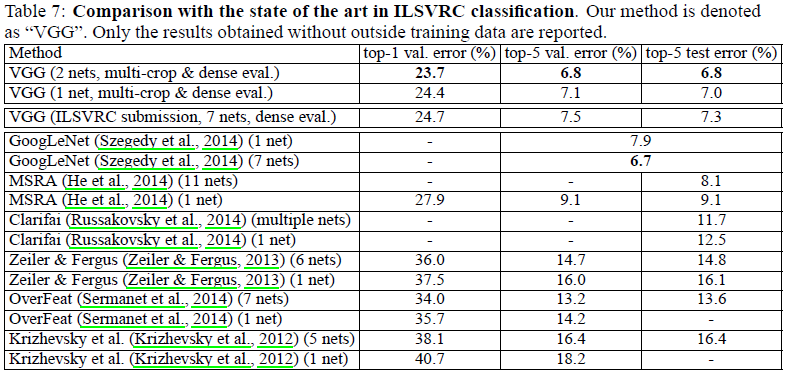
与ILSVRC-2012和ILSVRC-2013最好结果相比,VGGNet优势很大。与GoogLeNet对比,虽然7个网络集成效果不如GoogLeNet,但是单一网络测试误差好一些,而且只用2个网络集成效果与GoogLeNet的7网络集成差不多。
5 CONCLUSION
我们将卷积网络深度设置为19,相比于其他网络,VGGNet效果更好,并且在其他不同的任务或数据集上有很好的泛化能力。
参考
论文原文:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION