1. Keras简介
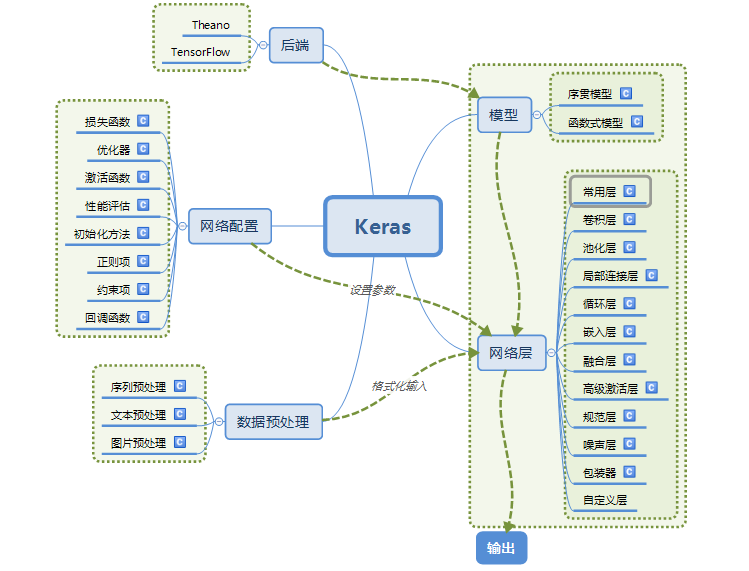
Keras是集成的神经网络的框架,它的后端是基于Tensorflow、Theano和CNTK的。
Keras的架构
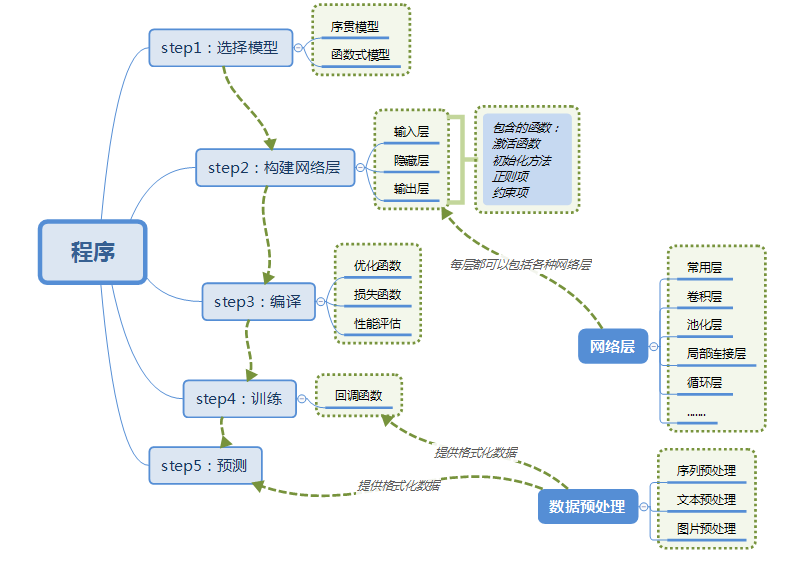
使用Keras的一般流程
2. 基本概念
符号计算
可以理解为计算图,计算图主要有两个元素组成:节点和边。节点通常来代表变量(scalar、vector、tensor等);边代表的是操作,即一些函数。
张量(tensor)
直接看作向量即可。
模型
Keras有两种模型:Sequential和函数式模型(Model),Sequential是函数式模型的特殊形式。
- Sequential:将多个网络层线性叠加,存入栈中的。单输入单输出,一条路通到底,层与层之间只是相邻关系,没有跨层连接。这么做的好处是:编译快,操作简单
- 函数式模型(Model):多输入多输出,层与层之间任意连接,但编译慢。
batch
以batch大小的数据集为梯度计算的基本单位。
3. Sequential模型
构造网络层
利用layer的list来构造该模型:
1
2
3
4
5
6from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([Dense(32, units=784), Activation('relu'),
Dense(10), Activation('softmax'),])
# Sequential的第一层需要接受一个关于输入数据shape的参数,后面的各层则可以自动的推导出中间数据的shape。利用
.add()方法加入layer:1
2
3
4
5
6
7model = Sequential()
model.add(Dense(32, input_shape(784,)))
model.add(Activation('relu'))
# input_shape是一个tuple类型的数据,传递给第一层
# 有些2D层,支持通过指定其输入维度input_dim来隐含的指定输入数据shape;
# 一些3D层,支持通过参数input_dim和input_length来指定输入shape;
# 如果你需要为输入指定一个固定大小的batch_size(常用于stateful RNN网络),可以传递batch_size参数到一个层中,例如你想指定输入张量的batch大小是32,数据shape是(6,8),则你需要传递batch_size=32和input_shape=(6,8)
编译
我们需要通过
compile来对学习过程进行配置,compile接收三个参数:优化器optimizer
损失函数loss
指标列表metrics
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 对于多分类问题
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# 对于二分类问题
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
# 对于回归问题
model.compile(optimizer='rmsprop', loss='mse')
# 用户自定义metrics
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])
训练
一般使用
fit函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# For a single-input model with 2 classes (binary classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, labels, epochs=10, batch_size=32)例子
卷积神经网络
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# Generate dummy data
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
model = Sequential()
# input: 100x100 images with 3 channels -> (100, 100, 3) tensors.
# this applies 32 convolution filters of size 3x3 each.
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
# 参数
# filters:卷积核的数目(即输出的维度)
# kernel_size:单个整数或由两个整数构成的list/tuple,卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度。
# strides:单个整数或由两个整数构成的list/tuple,为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rata均不兼容
# padding:补0策略,为“valid”, “same” 。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同,因为卷积核移动时在边缘会出现大小不够的情况。
# activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
# use_bias:布尔值,是否使用偏置项
# kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
# bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
# kernel_regularizer:施加在权重上的正则项,为Regularizer对象
# bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
# activity_regularizer:施加在输出上的正则项,为Regularizer对象
# kernel_constraints:施加在权重上的约束项,为Constraints对象
# bias_constraints:施加在偏置上的约束项,为Constraints对象
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
# 参数:
# lr:大于0的浮点数,学习率
# momentum:大于0的浮点数,动量参数
# decay:大于0的浮点数,每次更新后的学习率衰减值
# nesterov:布尔值,确定是否使用Nesterov动量
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)